 Abstract
Abstract
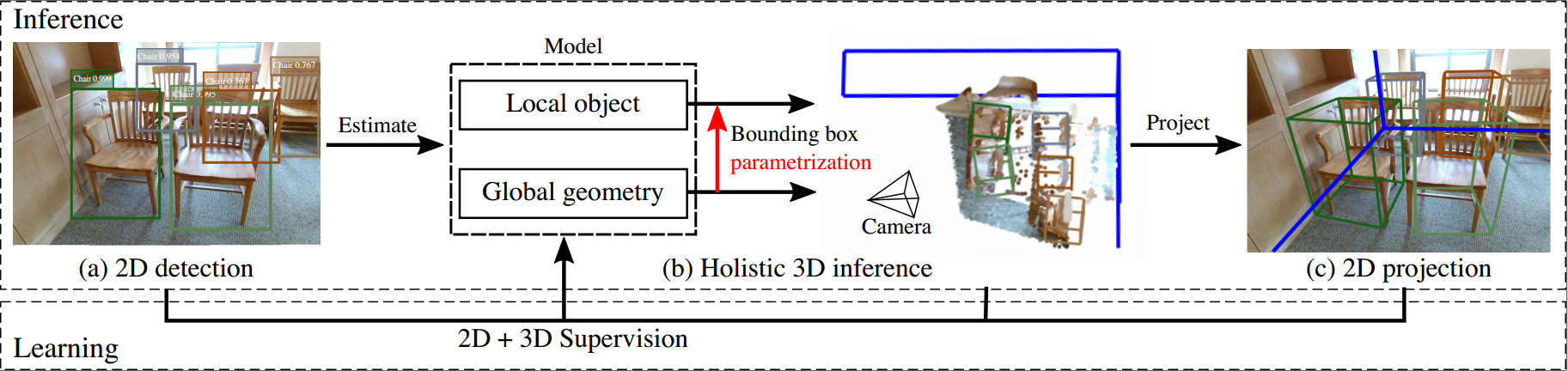
Holistic 3D indoor scene understanding refers to jointly recovering the i) object bounding boxes, ii) room layout, and iii) camera pose, all in 3D. The existing methods either are ineffective to address such a challenging problem or only tackle the problem partially. In this paper, we propose an end-to-end model that simultaneously solves all three tasks in real-time given only a single RGB image. The essence of the proposed method is to improve the prediction by i) parametrizing the targets (\eg, 3D boxes) instead of directly estimating the targets, and ii) cooperative training across different modules in contrast to training these modules individually. Specifically, we parametrize the 3D object bounding boxes by the predictions from several modules, \ie, 3D camera pose and object attributes. The proposed method provides two major advantages: i) The parametrization helps maintain the consistency between the 2D image and the 3D world, thus largely reducing the prediction variances in 3D coordinates. ii) Constraints can be imposed on the parametrization to train different modules simultaneously. We call these constraints "cooperative losses" as they enable the joint training and inference. Specifically, we employ three cooperative losses for 3D bounding boxes, 2D projections, and physical constraints to estimate a geometrically consistent and physically plausible 3D scene. Experiments on the SUN RGB-D dataset shows that the proposed method significantly outperforms prior approaches on 3D layout estimation, 3D object detection, and holistic scene understanding.






